Mastering sequence tagged sites is pivotal in leveraging modern data analytics for research and business intelligence. This advanced technique allows for more accurate and efficient data management, ensuring researchers and data analysts can unlock hidden patterns and insights that traditional methods may miss. By understanding the intricacies of sequence tagging, professionals can significantly enhance data retrieval and analysis processes.
Key insights box:
Key Insights
- Sequence tagged sites enable precise data tagging and retrieval, crucial for advanced analytics
- Techniques like Hidden Markov Models (HMM) and machine learning algorithms offer robust solutions for identifying sequence tagged sites
- Implementing sequence tagging enhances data accuracy and analytical outcomes
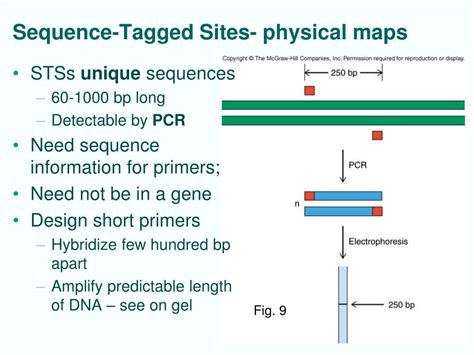
Understanding sequence tagged sites begins with recognizing their foundational role in structured data. These sites refer to specific locations within a dataset that hold sequences of data, often used in bioinformatics to mark genetic sequences or in text analytics for specific patterns of data points. This structural approach provides a framework for more efficient data management and analysis.
Sequence tagging fundamentally revolves around identifying and labeling sequences within data. The process involves delineating meaningful segments within a larger dataset, which can then be analyzed more effectively. For instance, in genomic studies, sequence tagging can help in identifying genes, protein coding regions, and regulatory elements. By tagging these sequences, researchers can streamline the complex data, making it more manageable and interpretable.
Technical considerations come into play when selecting the right tools for sequence tagging. Methods such as Hidden Markov Models (HMM) and machine learning algorithms like Long Short-Term Memory (LSTM) networks provide powerful frameworks for identifying sequences. HMM, for example, uses probabilities to find sequences that maximize the likelihood of correct tagging. On the other hand, LSTM networks excel at processing sequential data and are particularly useful in text analytics for tagging syntactical or grammatical structures.
When applied to practical scenarios, sequence tagging stands out for its ability to reduce data noise and enhance data quality. For instance, in natural language processing (NLP), tagging syntactic sequences can improve machine translation and sentiment analysis by providing clearer context and structure to the data. In a real-world case, a retail company implemented sequence tagging to analyze customer purchase patterns, resulting in more accurate forecasting models and targeted marketing strategies.
FAQ section:
What is the primary benefit of using sequence tagged sites?
The primary benefit is enhanced precision in data tagging and retrieval, leading to more accurate and efficient data analysis.
What tools are commonly used for sequence tagging?
Common tools include Hidden Markov Models (HMM) and machine learning algorithms like Long Short-Term Memory (LSTM) networks.
By mastering sequence tagged sites, professionals can significantly improve their analytical capabilities, leading to more insightful and actionable outcomes. It’s essential to adopt and refine these techniques to fully unlock their potential, ultimately driving more informed decision-making processes.


